The new method could revolutionize gene therapy and biotechnology by allowing precise activation or repression of genes in specific tissues.
(Bar Harbor, Maine – Oct. 23, 2024) – Researchers at The Jackson Laboratory (JAX), the Broad Institute of MIT and Harvard, and Yale University, have used artificial intelligence to design thousands of new DNA switches that can precisely control the expression of a gene in different cell types. Their new approach opens the possibility of controlling when and where genes are expressed in the body, for the benefit of human health and medical research, in ways never before possible.
“What is special about these synthetically designed elements is that they show remarkable specificity to the target cell type they were designed for,” said Ryan Tewhey, Ph.D., an associate professor at The Jackson Laboratory and co-senior author of the work. “This creates the opportunity for us to turn the expression of a gene up or down in just one tissue without affecting the rest of the body.”
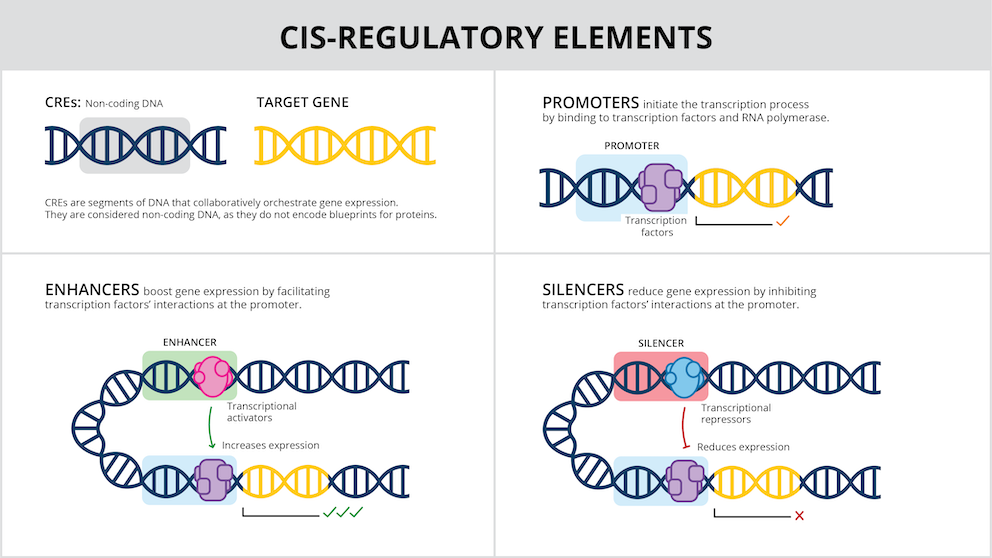
In recent years, genetic editing technologies and other gene therapy approaches have given scientists the ability to alter the genes inside living cells. However, affecting genes only in selected cell types or tissues, rather than across an entire organism, has been difficult. That is in part because of the ongoing challenge of understanding the DNA switches, called cis-regulatory elements (CREs), that control the expression and repression of genes.
In a paper published in Oct. 23 advanced online issue of Nature, Tewhey and his collaborators not only designed new, never-before-seen synthetic CREs, but used the CREs to successfully activate genes in brain, liver or blood cells without turning on those genes in other cell types.
Tissue- and time-specific instructions
Although every cell in an organism contains the same genes, not all the genes are needed in every cell, or at all times. CREs help ensure that genes needed in the brain are not used by skin cells, for instance, or that genes required during early development are not activated in adults. CREs themselves are not part of genes, but are separate, regulatory DNA sequences – often located near the genes they control.
Scientists know that there are thousands of different CREs in the human genome, each with slightly different roles. But the grammar of CREs has been hard to figure out, “with no straightforward rules that control what each CRE does,” explained Rodrigo Castro, Ph.D., a computational scientist in the Tewhey lab at JAX and co-first author of the new paper. “This limits our ability to design gene therapies that only affect certain cell types in the human body.”
“This project essentially asks the question: ‘Can we learn to read and write the code of these regulatory elements?’” said Steven Reilly, Ph.D., assistant professor of genetics at Yale and one of the senior authors of the study. “If we think about it in terms of language, the grammar and syntax of these elements is poorly understood. And so, we tried to build machine learning methods that could learn a more complex code than we could do on our own.”
Using a form of artificial intelligence (AI) called deep learning, the group trained a model using hundreds of thousands of DNA sequences from the human genome that they measured in the laboratory for CRE activity in three types of cells: blood, liver and brain. The AI model allowed the researchers to predict the activity for any sequence from the almost infinite number of possible combinations. By analyzing these predictions, the researchers discovered new patterns in the DNA, learning how the grammar of CRE sequences in the DNA impact how much RNA would be made – a proxy for how much a gene is activated.
The team, including Pardis Sabeti, MD, DPhil, co-senior author of the study and a core institute member at the Broad Institute and professor at Harvard, then developed a platform called CODA (Computational Optimization of DNA Activity), which used their AI model to efficiently design thousands of completely new CREs with requested characteristics, like activating a particular gene in human liver cells but not activating the same gene in human blood or brain cells. Through an iterative combination of ‘wet’ and ‘dry’ investigation, using experimental data to first build and then validate computational models, the researchers refined and improved the program’s ability to predict the biological impact of each CRE and enabled the design of specific CREs never before seen in nature.
"Natural CREs, while plentiful, represent a tiny fraction of possible genetic elements and are constrained in their function by natural selection," said study co-first author Sager Gosai, Ph.D., a postdoctoral fellow in Sabeti's lab. "These AI tools have immense potential for designing genetic switches that precisely tune gene expression for novel applications, such as biomanufacturing and therapeutics, that lie outside the scope of evolutionary pressures."
Pick-and-choose your organ
Tewhey and his colleagues tested the new, AI-designed synthetic CREs by adding them into cells and measuring how well they activated genes in the desired cell type, as well as how good they were at avoiding gene expression in other cells. The new CREs, they discovered, were even more cell-type-specific than naturally occurring CREs known to be associated with the cell types.
"The synthetic CREs semantically diverged so far from natural elements that predictions for their effectiveness seemed implausible," said Gosai. "We initially expected many of the sequences would misbehave inside living cells."
“It was a thrilling surprise to us just how good CODA was at designing these elements,” said Castro.
Tewhey and his collaborators studied why the synthetic CREs were able to outperform naturally occurring CREs and discovered that the cell-specific synthetic CREs contained combinations of sequences responsible for expressing genes in the target cell types, as well as sequences that repressed or turned off the gene in the other cell types.
Finally, the group tested several of the synthetic CRE sequences in zebrafish and mice, with good results. One CRE, for instance, was able to activate a fluorescent protein in developing zebrafish livers but not in any other areas of the fish.
“This technology paves the way toward the writing of new regulatory elements with pre-defined functions,” said Tewhey. “Such tools will be valuable for basic research but also could have significant biomedical implications where you could use these elements to control gene expression in very specific cell types for therapeutic purposes.”
About The Jackson Laboratory
The Jackson Laboratory is an independent, nonprofit biomedical research institution with a National Cancer Institute-designated Cancer Center and more than 3,000 employees in locations across the United States, Japan and China. Its mission is to discover precise genomic solutions for disease and to empower the global biomedical community in the shared quest to improve human health. For more information, please visit www.jax.org.
About Broad Institute of MIT and Harvard
Broad Institute of MIT and Harvard was launched in 2004 to empower this generation of creative scientists to transform medicine. The Broad Institute seeks to describe the molecular components of life and their connections; discover the molecular basis of major human diseases; develop effective new approaches to diagnostics and therapeutics; and disseminate discoveries, tools, methods and data openly to the entire scientific community.
Founded by MIT, Harvard, Harvard-affiliated hospitals, and the visionary Los Angeles philanthropists Eli and Edythe L. Broad, the Broad Institute includes faculty, professional staff and students from throughout the MIT and Harvard biomedical research communities and beyond, with collaborations spanning over a hundred private and public institutions in more than 40 countries worldwide.
Media contacts:
Cara McDonough
The Jackson Laboratory
cara.mcdonough@jax.org
Cell: 919-696-3854
Karen Zusi-Tran
Broad Institute of MIT and Harvard
kzusi@broadinstitute.org
Office: 617-714-8011